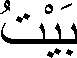|
|
Detecting Text Boundaries |
You'll need to locate character boundaries if your application allows the end-user to highlight individual characters, or to move a cursor through text a character at a time. To create aBreakIteratorthat locates character boundaries, you invoke thegetCharacterInstancemethod:This type ofBreakIterator characterIterator = BreakIterator.getCharacterInstance(currentLocale);BreakIteratordetects boundaries between user characters, not just Unicode characters. User characters differ with language, but theBreakIteratorclass can recognize these differences because it is locale-sensitive. A user character may be composed of more than one Unicode character. For example, the user character ü can be composed by combining the Unicode characters '\u0075' (u) and '\u00a8' (¨). This isn't the best example, however, because the character ü may also be represented by the single Unicode character '\u00fc'. We'll draw upon the Arabic language for a more realistic example.In Arabic the word for house is:
Although this word contains three user characters, it is composed by six Unicode characters:The Unicode characters at positions 1, 3, and 5 in theString house = "\u0628" + "\u064e" + "\u064a" + "\u0652" + "\u067a" + "\u064f";housestring are diacritics. In Arabic diacritics are required, because they can alter the meanings of words. The diacritics in our example are non-spacing characters since they appear above the base characters. In an Arabic word processor, we cannot move the cursor on the screen once for every Unicode character in the string. Instead, we must move it once for every user character, which may be composed by more than one Unicode character. Therefore, we must use aBreakIteratorto scan the user characters in the string.In our sample program, BreakIteratorDemo.java, we create a
BreakIteratorto scan Arabic characters. Then we pass thisBreakIterator, along with theStringobject we created previously, to a method namedlistPositions:TheBreakIterator arCharIterator = BreakIterator.getCharacterInstance(new Locale ("ar","SA")); listPositions (house,arCharIterator);listPositionsmethod uses aBreakIteratorto locate the character boundaries in the string. Note that we assign a particular string to theBreakIteratorwith thesetTextmethod. We retrieve the first character boundary with thefirstmethod, then invoke thenextmethod until the constantBreakIterator.DONEis returned. The code for this routine is as follows:Thestatic void listPositions(String target, BreakIterator iterator) { iterator.setText(target); int boundary = iterator.first(); while (boundary != BreakIterator.DONE) { System.out.println (boundary); boundary = iterator.next(); } }listPositionsmethod prints out the following boundary positions for the user characters in the stringhouse. The positions of the diacritics (1, 3, 5) are not listed:0 2 4 6
|
|
Detecting Text Boundaries |